On March 29, Elon Musk tweeted this (https://twitter.com/elonmusk/status/1773655245769330757 ):
"Should be available on 𝕏 next week. Grok 2 should exceed current AI on all metrics. In training now."
Is that so? Let's find out.
Note that for this purpose it counts as 'Grok 2' even if it is renamed - the only way a newly announced xAI model does not count as that is if it is named Grok 1.X, or otherwise is clearly pre-2, but the thing in training now counts whatever they ultimately call it, if they release it, etc.
Resolves YES if Grok 2 is released and it exceeds or ties (to 1 decimal place) Claude 3 Opus and all metrics for models available to the public in some form on or before 3/28/24 on everything in this chart:

So MMLU, GPQA, GSM8K, AMTH, MGSM, HumanEval, DROP, Big-Bench-Hard, ARC-Challenge and HellaSwag.
Resolves NO if Grok 2 is released and does NOT exceed or tie these numbers on one or more of these metrics, or if Grok 2 is not released by EOY 2025.
If xAI does not test on all of these metrics, but it succeeds on all metrics that it does test, and there is no way to test on the others, I will use best judgment - if it clearly would have exceeded I will still resolve YES, but by default (or if it would have been close) I will assume they chose which metrics to test on based on results, and be inclined to count that as NO. Will clarify further if this gets a lot of interest, as needed.
Are we not making any progress on getting an actual result? Is this still actually unclear?
Seems like we should find a way to wrap this up soon, but the market reflects real uncertainty on the outcome. Can no one find a way to check?
I've moved the deadline forward to 12/24/24, as a 'this is when I just use my best judgment' date.
@ZviMowshowitz Both Drop and MGSM are considered to be saturated by OpenAI (https://github.com/openai/simple-evals) and there seem to be significant problems with DROP (https://huggingface.co/blog/open-llm-leaderboard-drop).
Taken literally, I'm at 35% on this -- sheer randomness suggests underperformance on one of these benchmarks.
In the spirit of the question, this is quite likely "yes" - even lmsys (style control) shows Grok at LLama 3.1 405 level, which seems to beat Opus on any metric I can find.
Beating both Drop and Gsm8k may be difficult. First benchmark is known to not be steadily progressing on the GPT4 series; second is so close to saturation randomness affects results.
Note that resolving this question might require running tests on GPT-4-0125-preview.
What if Grok 2 is bad but gets much better within the year? https://x.com/rohanpaul_ai/status/1823814591157297567
Some think the current thing is "early"
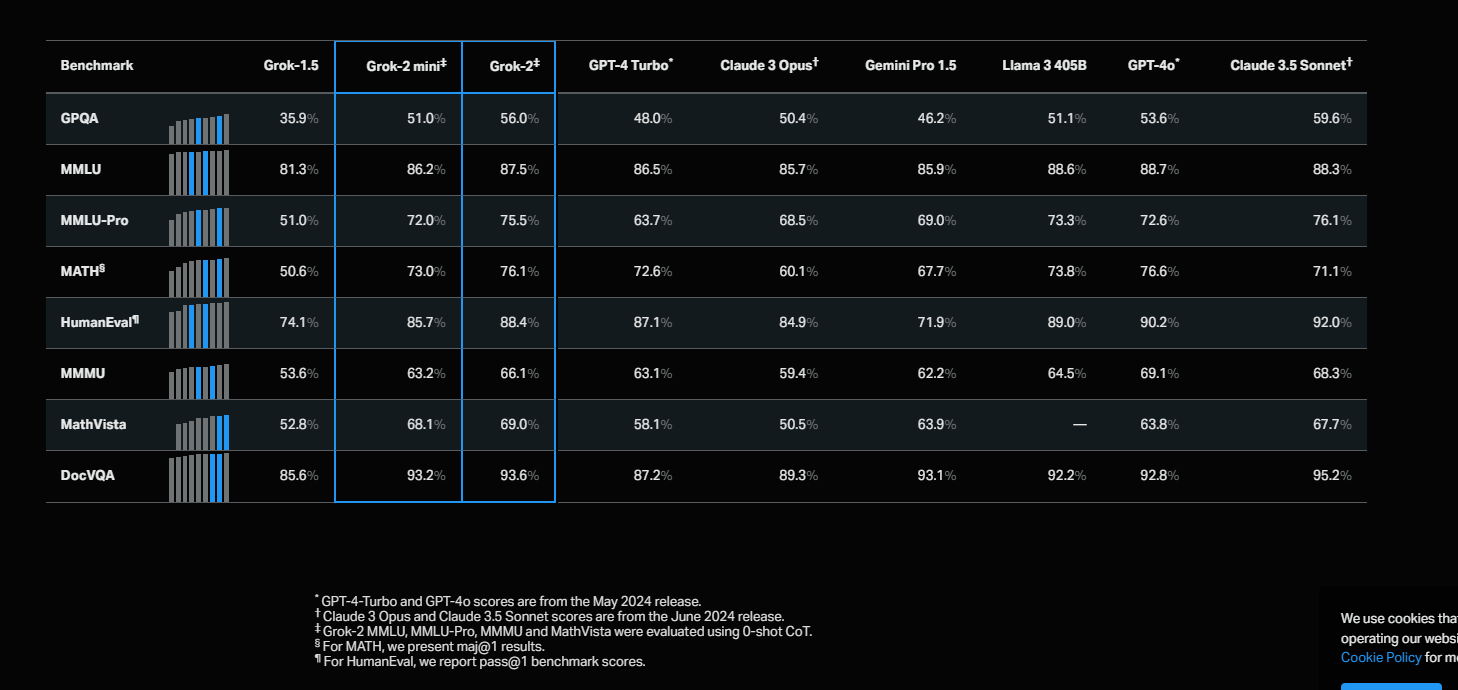
It beats opus on every benchmark that is still tested (some of them in the image are outdated like GSM8K) https://x.ai/blog/grok-2
@ZviMowshowitz FYI these choices frequently flip the order of model performance.
@ZviMowshowitz Will you resolve this question NO, if X-Twitter fails to release Grok 2 by some deadline?